




Getting Started with Robots.txt and Sitemaps for Web Scraping

In the vast digital landscape, where countless websites compete for attention, it's crucial to understand the rules of engagement. For web developers, SEO professionals, and content creators, decoding robots.txt is key to ethical and effective web scraping. This guide will help you understand how to responsibly interact with websites using robots.txt and sitemaps.
Understanding the Role of Robots.txt in Web Crawling
Web crawling is at the heart of how search engines discover and index content on the internet. Websites use robots.txt files as a primary tool to manage and control this crawling behavior. These files serve as a set of instructions for web robots, including search engine bots, guiding them on what content to access or ignore.
The purpose of robots.txt is twofold. It helps site owners protect sensitive information and optimize server performance, while also providing a framework for ethical web scraping.
Understanding Robots.txt
To illustrate how robots.txt operates, let's consider the example of this website. A typical robots.txt file includes directives like User-agent, Disallow, and Allow.
- User-agent specifies which bots should follow the rules. For instance, "User-agent: *" applies to all bots.
- Disallow prevents bots from accessing specific areas, such as administrative sections or private directories.
- Allow grants access to particular resources, ensuring dynamic files essential for site functions are reachable.
On this website, the robots.txt file appears as follows:
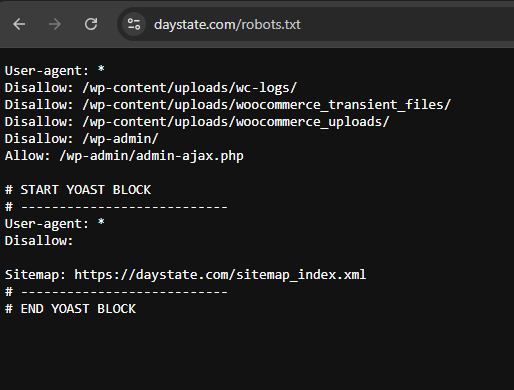
- As you can see this website Disallows Access to these URL paths:
/wp-content/uploads/wc-logs//wp-content/uploads/woocommerce_transient_files//wp-content/uploads/woocommerce_uploads//wp-admin/(WordPress admin area)
- Allow Access specifically to
/wp-admin/admin-ajax.php, allowing crawlers to reach this file for necessary AJAX functionality. - Yoast SEO Block:
- The line
Disallow:is empty, meaning no additional restrictions are added by this block. - Sitemap provided:
https://daystate.com/sitemap_index.xml, which helps search engines locate all key URLs for indexing.
- The line
What is a Sitemap?
A sitemap is a crucial component of a website, listing all its important URLs. It acts as a roadmap for search engines, allowing them to quickly discover and index new or updated content.
For site owners, sitemaps are invaluable. They ensure that all relevant pages are visible to search engines, facilitating better indexing and ranking. The benefits of sitemaps extend beyond SEO, aiding in user experience by ensuring content is easily discoverable.
https://daystate.com/robots.txt robots.txt file includes a link to its sitemap, providing a structured path for search engines to follow. This link is essential for efficient crawling and indexing of the site's content.
Here's what the daystate's sitemap looks like:
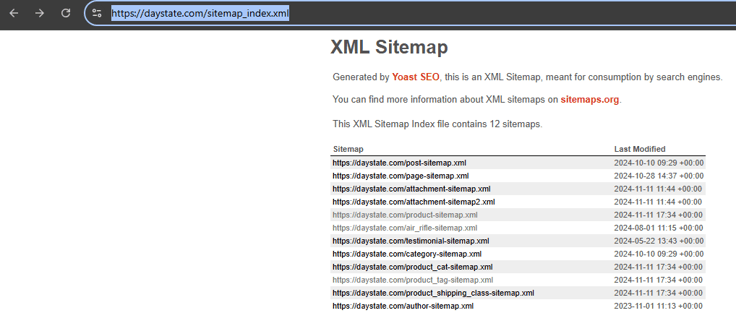
For instance, let's go ahead and click on "https://daystate.com/product-sitemap.xml"
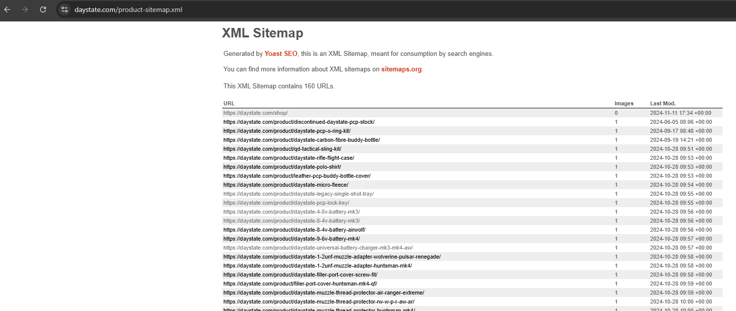
As you can see, we can see all the URLs for the "Products" in this scenario. Below is a Python script designed to scrape each product. It begins by parsing the XML page of products to extract all product URLs, then iterates through each URL to extract the product title and price.
import re
import requests
from bs4 import BeautifulSoup
def fetch_xml_sitemap(sitemap_url) -> str:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
response = requests.get(sitemap_url, headers=headers)
response.raise_for_status() # Check for request errors
return response.content
def extract_endpoints(response_content):
output_endpoints = []
soup = BeautifulSoup(response_content, "xml")
# Loop through each product entry in the sitemap
for url in soup.find_all("url"):
# Extract link, last modified date, and image (if available)
endpoint = url.find("loc").text if url.find("loc") else None
if endpoint is not None:
output_endpoints.append(endpoint)
return output_endpoints
def extract_product_info(product_url):
headers = {
"User-Agent": "input_user_agent"}
proxy = {
"http": "http://username:[email protected]:6060",
"https": "http://username:[email protected]:6060"
}
response = requests.get(product_url, headers=headers, proxies=proxy)
soup = BeautifulSoup(response.content, "html.parser")
pattern = re.compile(r"^product-\d+$")
try:
product_div = soup.find("div", id=pattern)
product_title = product_div.find("h1", {"class":"product_title entry-title"}).text
product_price = product_div.find("bdi").text
return product_title, product_price
except:
print("Error Extracting Product Information")
return None, None
if __name__ == '__main__':
url_sitemap = "https://daystate.com/product-sitemap.xml"
sitemap_xml = fetch_xml_sitemap(url_sitemap)
sitemap_urls = extract_endpoints(sitemap_xml)
for url in sitemap_urls:
print(extract_product_info(url))Why Both Files Matter for SEO and Web Scraping
Together, robots.txt files and sitemaps form the backbone of SEO and ethical web scraping practices. Robots.txt guides web crawlers on permissible areas, safeguarding sensitive data and reducing server load. Meanwhile, sitemaps boost content discovery by search engines, ensuring new pages are promptly indexed.
For web scrapers, respecting these files is paramount. Ignoring robots.txt directives can lead to penalties, damaging both reputation and search engine rankings. Ethical scrapers follow these guidelines, promoting a respectful digital environment.
Conclusion
Robots.txt files and sitemaps are indispensable tools in web crawling. They provide a structured approach to managing site access and indexing, benefiting both site owners and web scrapers.
By understanding and respecting these elements, you can optimize your digital strategies, enhance SEO, and engage in ethical web scraping practices. Remember, responsible usage maintains the balance of the web ecosystem, ensuring a positive experience for all stakeholders.