





The web browsers use Javascript to create a dynamic and interactive experience for the user. Majority of the applications and functions making the Internet indispensable to modern life are encoded in the form of Javascript. Considering the early incarnations of Javascript, the web pages were static, and offered a little user interaction beyond clicking links
Table of Contents
- Why Do You Need To Scrape a Javascript Website?
- Scraping a Javascript Website Using Python Installing Selenium libraryInstalling Web driverExample
- Installing Selenium library
- Installing Web driver
- Example
- Using a Proxy
- Why Use Proxies For Scraping a JS Website
- Conclusion
The web browsers use Javascript to create a dynamic and interactive experience for the user. Majority of the applications and functions making the Internet indispensable to modern life are encoded in the form of Javascript. Considering the early incarnations of Javascript, the web pages were static, and offered a little user interaction beyond clicking links and loading new pages.
Following are some of the dynamic website enhancements that are performed by Javascript.
- Input validation from web forms
- Animation of page elements such as resizing, relocating, and fading
- Loading new data without reloading the page
- Playing audio and video
- Repairing the browser compatibility issues
You can use scraping to collect structured data from websites in an automated fashion. Web scraping is also known as web data extraction. Some of the main use cases of web scraping are as:
- News monitoring
- Price intelligence
- Lead generation
- Price monitoring
- Market research
Let’s first understand the need to scrape websites.
Why Do You Need To Scrape a Javascript Website?
The businesses use web scraping to make use of the vast amount of publicly available data for making smarter decisions. Below are some of the areas where web scraping is used.
- eCommerce
- Social Media
- Banking
- Finance
- Marketing
- Real Estate
- Finance
- Search Engine Optimization
- Sales leads

Following are the reasons due to which companies need to scrape the websites.
Automation – It is not possible to copy and paste each piece of information from a website. The companies use scraping softwares to automate most of their associated processes.
Data Management – You can not use databases and spreadsheets to manage numerals and figures on a website configured in HTML. So, the companies use web scraping tools for managing their data.
Real Estate Listing – The real estate agents use web scraping for populating their database of available properties for rent or for sale.
Shopping Site Comparison Data – The companies use web scraping to scrape pricing and product data from each retailer, so that they can provide their users with the comparison data they desire.
Industry Statistics and Insights – The companies use scraping for building massive databases and drawing industry-specific insights from these. For instance, a company can scrape and analyze tons of data about oil prices. It can then sell their insights to oil companies across the world.
Scraping a Javascript Website Using Python
Let’s see how you can use Selenium to scrape Javascript websites.

Installing Selenium library
You can install Selenium using the following command.
pip install seleniumInstalling Web driver
Do you know Selenium simulates an actual browser? It does not use your chrome installation, rather it uses a driver to run a browser. The Selenium web drivers refer to both the language bindings and the implementations of the individual browser controlling code. You have to download the web driver, and can add it to the path environment variable. We will be using the Firefox web driver and you can install it by following this link.
Example
Let us consider a simple selenium example that involves collecting a website title. For this, we will first import webdriver from selenium in a python file as shown below:
from selenium import webdriverWe have to mention the path where the webdriver is located. Afterwards, we have to initialize the Firefox web driver.
WEBDRIVER_PATH = './'
driver = webdriver.Firefox(WEBDRIVER_PATH)Now we define the URL to get the title of the website.
URL = 'https://www.google.com'
driver.get(URL)
print (driver.title)Running the above code opens a firefox window that prints into the console the title of the website. We defined the URL of Google as an example in this case, so the result will be like this:
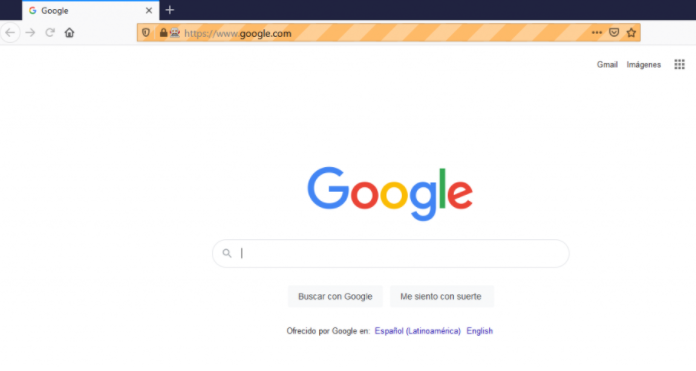
This is the google page from the firefox web driver. The title printed on the console will be as:
We have to manually close the firefox window that was opened. We will add driver.quit() at the end of our code so that the window will be automatically closed after the job is done.
from selenium import webdriver
WEBDRIVER_PATH = './'
driver = webdriver.Firefox(WEBDRIVER_PATH)
URL = 'https://www.google.com'
driver.get(URL)
print (driver.title)
driver.quit()In case you want to collect data from a dynamic website, you can follow the same steps mentioned above. For instance, if you want to retrieve the Youtube title, you can use the below code.
from selenium import webdriver
WEBDRIVER_PATH = './'
driver = webdriver.Firefox(WEBDRIVER_PATH)
URL = 'https://www.youtube.com'
driver.get(URL)
print (driver.title)
driver.quit()Let’s try something new here. We can edit the search box and fill it with the word “Selenium” by using the “Keys” class as shown below.
from selenium.webdriver.common.keys import KeysAfter initializing the firefox web driver and getting the Youtube title, we create an object that contains the search box with xpath.
search_box = driver.find_element_by_xpath('//input[@id="search"]')We then edit the content of the search box and fill it with the word “Selenium”.
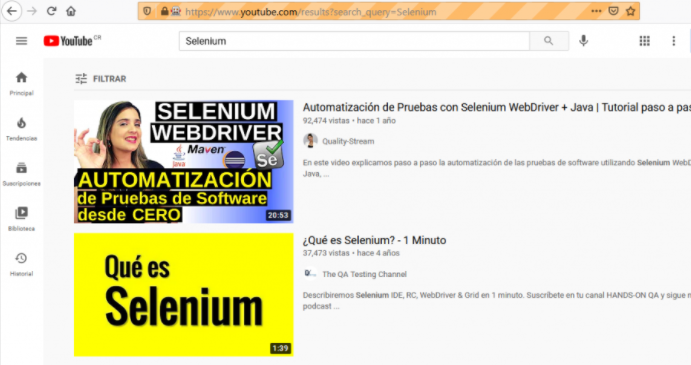
search_box.send_keys('Selenium')Once we fill the search box with our desired content, we can press “Enter” to make the search active.
search_box.send_keys(Keys.ENTER)You can see in the below image that the Youtube search box contains the word “Selenium”.
Using a Proxy
The proxies are required when you need a localized web content. They are also required when you send too many requests to a website in a short period of time. You need proxies for Selenium when automated testing is required. However, in order to use a Selenium proxy for scraping a Javascript website, you need to use a Selenium wire that extends Selenium’s bindings and gives access to the underlying requests made by the browser.
For using Selenium with a proxy, the following is the package you need to install.
from selenium wire import webdriverAfter installing the Python selenium-wire library, you need to mention the following:
- proxy_username
- proxy_password
- proxy_url
- proxy_port
Here we mentioned a random port number 8080 as an example. You can set the username, password and URL of the desired website of your own choice.
proxy_username = "USER_NAME"
proxy_password = "PASSWORD"
proxy_url = "Any Website URL"
proxy_port = 8080
options = {
"proxy": {
"http": f"http://{proxy_username}:{proxy_password}@{proxy_url}:{proxy_port}",
"verify_ssl": False,
},
}For the Selenium web driver, residential proxies are the best choice. It is because they do not get easily detected unlike datacenter proxies. They route clients’ requests through residential IPs and earn more trust than datacenter IPs. They are also useful in accessing complex websites that use Javascript like Youtube, Google, Instagram etc.
Why Use Proxies For Scraping a JS Website
You need to use proxies for scraping a website because of the following reasons:
- Proxies are used for improving security and balancing the internet traffic of a website.
- The web scrapers need to use proxies for hiding their identity and making their traffic look like regular user traffic.
- The proxies are also used to protect the personal data of web users.
- Proxies help in accessing the websites that are blocked by the country’s censorship mechanism.
- You can crawl websites using proxies in a reliable manner.
- Proxies are valuable when you need to scrape product data from online retailers. It is because they enable you to make your request from a particular geographical region, and you can access the specific content the website displays for that location.
- Proxies help you to make a large number of requests to the target website without getting banned.
- You can use proxies to make unlimited concurrent connections to the same or different websites.

Conclusion
Web scraping is important as you can use it for:
- Scraping product/services ad and make insights into their budgets
- Predicting the fashion trend to stay competitive
- Scraping social media channels and discovering potential customers etc.
Further we discussed how you can use Selenium to scrape Javascript featured websites in Python. You can scrape content of static websites as well as dynamic websites like Youtube. You also need to use Selenium proxies for automated testing. The best proxies you can use are the residential proxies as they are super fast and can not be easily detected unlike other proxies.
Hope you got an understanding of how to scrape a Javascript website using Python.